ExtremePrecipit - Caractérisation des précipitations extrêmes horaires en France
précipitations extrêmes, climat, modélisation climatique, changement climatique, France, adaptation territoriale, risques climatiques
TRANSFORMER 10 MILLIARDS DE POINTS DE DONNÉES CLIMATIQUES EN DÉCISIONS DE GESTION DES RISQUES.
- Expert-Validated : projet réalisé en collaboration étroite avec le CNRS, Météo-France et l’IGE.
- Autorité scientifique : méthodologie soumise à la revue internationale de rang A HESS (Copernicus) (1).
- Big Data : traitement de 10 milliards de points (100 Go) sur 63 ans d’historique.
- Ingénerie : pipeline distribué (96 workers) : gain de performance de 80%.
- Statistiques : modélisation des extrêmes par GEV non-stationnaire (7 modèles auto-sélectionnés).
- Industrialisation : architecture Cloud-Native (Zarr, Parquet) avec CI/CD complète et monitoring.
Le challenge technique était de concevoir une infrastructure capable d’ingérer, de transformer et de modéliser l’évolution des pluies extrêmes horaires en France (1959–2022). Un pont entre la donnée brute (NetCDF) et la décision (Dashboard/Rapport).
1 Contexte et problématique
Le réchauffement climatique n’est plus une abstraction : +1,7°C en France, +2°C dans les Alpes (2). Cette énergie thermique se traduit par une intensification brutale du cycle de l’eau (relation de Clausius-Clapeyron : +7% d’humidité par °C).
La problématique : si les extrêmes journaliers sont suivis, les précipitations horaires — responsables des crues éclair et des catastrophes urbaines — restaient jusqu’ici dans l’ombre.
- Absence de données globalisées à haute résolution.
- Complexité statistique des phénomènes convectifs locaux.
- Incertitude critique sur la fiabilité des modèles climatiques actuels.
2 Données
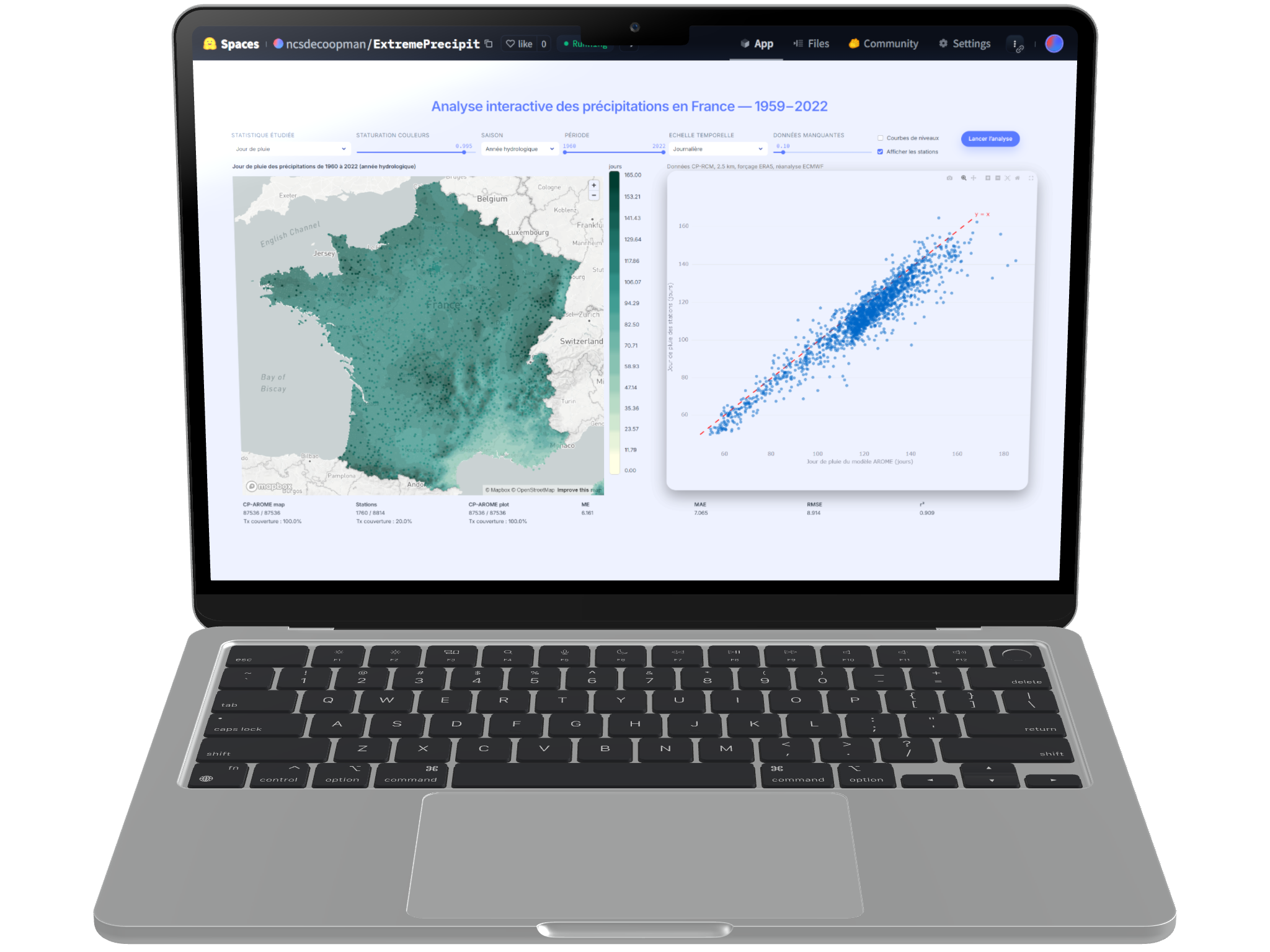
Ce projet exploite la simulation CNRM-AROME (2,5 km) forcée par ERA5 (1959–2022). C’est l’un des rares modèles au monde capable de simuler explicitement la convection profonde (climatologie à convection permise). Les données pluviométriques horaires recueillies par Météo-France servent de référence absolue pour la validation.
3 Approche et méthodologie
3.1 Workflow et architecture
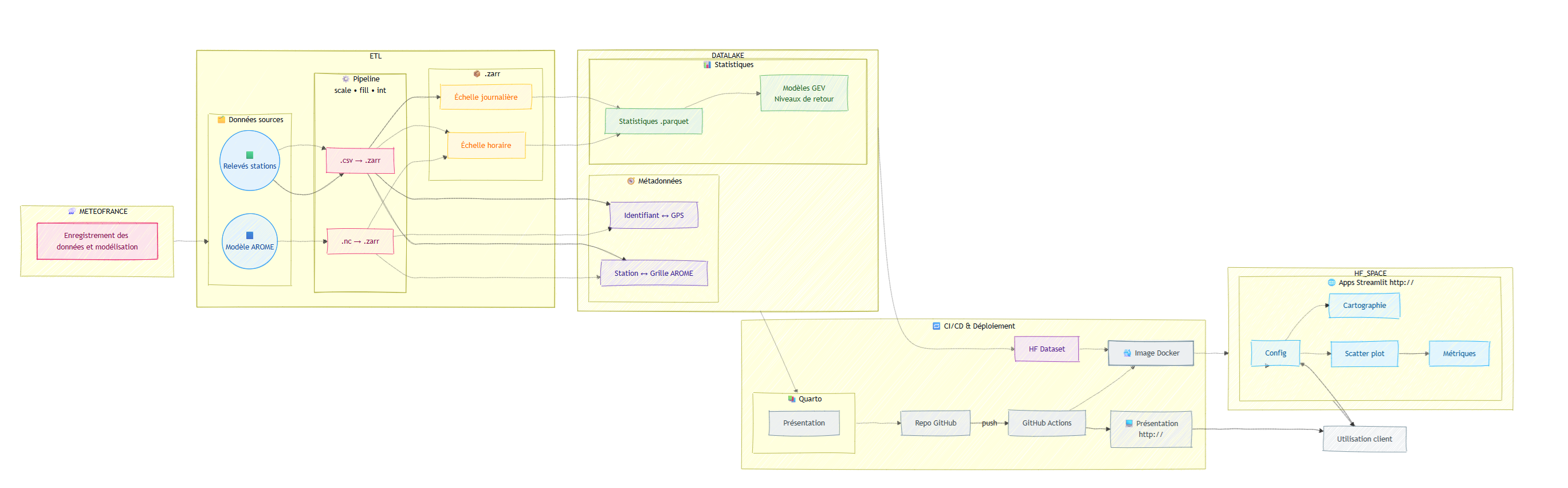
L’infrastructure repose sur un pipeline de production automatisé, garantissant traçabilité et performance :
- Ingestion et standardisation : conversion des formats complexes (NetCDF) en formats cloud-native (Zarr, Parquet) pour un accès distribué.
- Processus Big Data : extraction des maximas annuels sur cluster HPC (distribution via Dask).
- Modélisation avancée : ajustement des lois GEV et détection de tendances non-stationnaires par point de grille.
- Distribution des résultats : déploiement d’une application Streamlit interactive et génération de rapports automatisés via Quarto.
3.2 Pourquoi cette architecture ?
- Partitionnement physique fin : un fichier Parquet par combinaison (donnée/année/saison) pour des chargements atomiques et ultra-rapides.
- Infrastructure frugale : hébergement statique sur Hugging Face, éliminant les coûts de serveurs SQL tout en maintenant une performance “Ready-to-Scale”.
- Reproductibilité totale : pipeline versionné, configuration As-Code (YAML), et déploiement via Docker/CI/CD.
3.3 Expertise technique et impact
3.3.1 Data Engineer (scalabilité et HPC)
- Architecture ETL / ELT : pipeline de conversion massive NetCDF vers Zarr avec chunking adaptatif et filtrage géospatial.
- Calcul distribué : parallélisation via
DasketProcessPoolExecutor(96 workers) avec un gain de performance de 80 % sur 100 Go de données. - Stockage cloud-native : optimisation du stockage via formats segmentés (Zarr, Parquet) avec compression spécifique pour accès concurrent.
- Fiabilité du système : orchestration robuste et gestion fine des ressources mémoire (
Xarraycaching). - MLOps & DevOps : CI/CD (GitHub Actions), conteneurisation (Docker), et versionnement de datasets sur HuggingFace.
3.3.2 Data Scientist (modélisation avancée et gestion du risque)
- Extreme Value Theory : modélisation GEV (Generalized Extreme Value) pour la quantification des risques rares (crues, inondations).
- Robustesse statistique : sélection automatique parmi 7 modèles via Likelihood Ratio Test et calcul de p-values.
- Optimisation numérique : accélération des calculs de vraisemblance profilée via Numba et solveurs de racines avancés.
- Validation scientifique : évaluation rigoureuse vs. observations (biais et corrélations) et publication dans la revue HESS (Copernicus).
- Analyse décisionnelle : conception de dashboards interactifs (Streamlit, Leafmap) pour transformer la statistique en vision territoriale.
4 Technologies utilisées
- Data Backbone :
Zarr,Parquet,HuggingFace Datasets(stockage distribué et versionné). - Compute Engine :
Dask,Polars,Xarray,Numba(performance brute et parallélisation). - Modeling Stack :
Extreme Value Theory,GEV,Scipy Stats,Log-Likelihood Profiling. - Infrastructure :
Docker,GitHub Actions,Airflow,Linux HPC Cluster. - UX / Vision :
Streamlit,Quarto,Plotly,GeoPandas(reporting automatisé).
5 Lien vers le projet
- L’article est accessible sur EGUsphere.
- Le rapport est accessible en PDF.
- Les cartes générées sont accessibles en PDF.
- Les présentations Master 2 - UGA et Météo-France (enregistrement vidéo) sont également disponibles.
- Le code source est accessible sur GitHub.
- L’application est accessible sur HuggingFace.
6 Cas d’usage et perspectives
Cette étude présente plusieurs opportunités dans le cadre d’applications pratiques. Premièrement, les résultats permettraient une meilleure anticipation des événements météorologiques extrêmes, essentielle pour la gestion des risques liés aux inondations et aux dégâts associés aux fortes précipitations. Les collectivités territoriales pourraient utiliser ces informations pour adapter leurs plans de prévention des risques naturels (PPRN) et renforcer leur résilience face au changement climatique.
Deuxièmement, l’évaluation fine et spatialisée des précipitations extrêmes horaires fournirait aux gestionnaires des ouvrages hydrauliques, comme EDF, des données cruciales pour optimiser la gestion des réservoirs et la sécurité des barrages en période de crise.
Enfin, à plus long terme, les résultats pourraient servir de base à des projections climatiques locales, alimentant les stratégies d’adaptation au changement climatique dans différents secteurs (urbanisme, agriculture, infrastructures).